

Auch wenn die meisten von ihnen inzwischen mit Graphics Processing Units (GPU) arbeiten: Sprachmodelle an Supercomputern zu trainieren, ist keine Selbstverständlichkeit. „Die Entwickler von weit verbreiteten Large Language Models oder LLM trainieren natürlich auf Hochleistungs-Systemen, die speziell für solche Jobs aufgebaut und optimiert werden“, erläutert Ajay Navilarekal Rajgopal, Informatiker im Big Data & AI-Team des Leibniz-Rechenzentrums (LRZ). „Supercomputer für Forschung und Wissenschaft erfüllen dagegen ein viel breiteres Aufgabenspektrum.“ SuperMUC-NG Phase 2 (SNG-2), das aktuelle LRZ-Flaggschiff, erstellt Simulationen für unterschiedlichste Forschungssparten, rechnet komplexe Gleichungen – und kann eingesetzt werden, um Sprachmodelle auszuarbeiten: „Die meisten GPT-Modelle wurden auf der CUDA-Umgebung von NVIDIA trainiert“, berichtet Rajgopal. „Für die Implementierung auf SNG-2, der ja mit Intel-Beschleunigern arbeitet, sind jedoch nur kleine Software-Anpassungen notwendig.“
Gemeinsam mit dem Computerlinguisten Nikolai Solmsdorf, Software-Ingenieur bei Intel, hat Rajgopal den Trainingsaufbau von GPT-Modellen evaluiert und dabei besonders auf die Effizienz der GPU-Auslastung geachtet: „Wir konnten auf fast der Hälfte des Systems GPT-Style-Modelle ohne große Performance-Verluste trainieren. Das ist schon ein sehr gutes Ergebnis.“ Während der ISC stellen beide Forscher ihre Ergebnisse vor.
Generative, vortrainierte Transformer (GPT) sind das Fundament aktueller großer Sprachmodelle oder LLM: Diese sind schichtweise aus einzelnen neuronalen Netzen aufgebaut, die zusammen Hunderte von Milliarden Parameter berücksichtigen, und beinhalten zusätzlich Transformer oder mathematische Aufmerksamkeitsmechanismen, die Prozesse im menschlichen Hirn beim Sprechen und Lesen nachahmen. Damit werten diese Programme massenweise Sprache aus, um schließlich selbst Wörter, Sätze, Texte nach statistischen Wahrscheinlichkeiten zu formen.
Rajgopal und Solmsdorf experimentierten mit dem Trainingsaufbau für GPT-Modelle unterschiedlicher Größe mit 3,6 Milliarden, 20 Milliarden oder 175 Milliarden Parametern. Zum Vergleich: Chat-GPT, Version 5, verfügt nach Schätzungen über zwei bis fünf Billionen Parameter. Diese Größenverhältnisse verdeutlichen, dass LLM samt der Trainingsdaten auf mehrere GPU und über Rechenknoten skaliert und verteilt werden müssen.
Dafür gibt es verschiedene Strategien (s. Grafik unten), die jeweils unterschiedlich Einfluss nehmen auf die verfügbaren Speicher- und Netzkapazitäten:
Die Mischung macht's: Fürs Training von Sprachmodellen können Modelle sowie Datensätze unterschiedlich auf die GPU verteilt werden. Das wirkt sich auf die Rechenleistung oder auf den Datentransfer zwischen Rechen- und Speichereinheit aus, damit wurde für die Studie experimentiert. Als sehr effizient stellte sich die automatisierte Verteilung heraus. Grafik generiert mit NotebookLM von © A. N. Rajgopal| LRZ
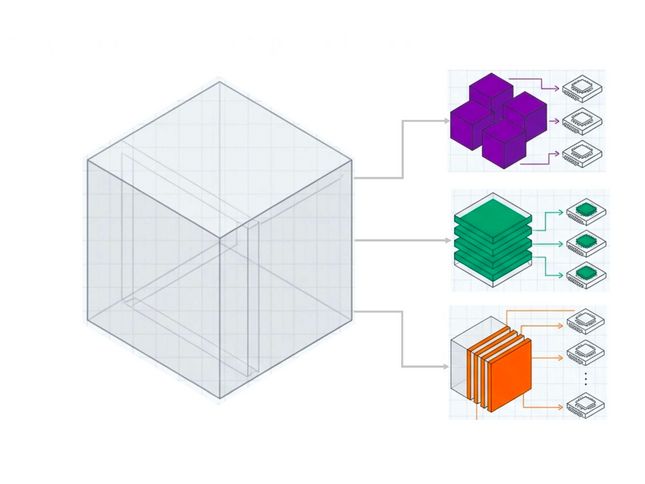
„Müssen die Layer für die Tensor-Parallelisierung auf mehrere Rechenknoten des SNG-2 verteilt werden, dann ist mit Verlust der GPU-Effizienz zu rechnen“, berichtet Rajgopal die wichtigsten Erfahrungen. „Bei der Pipeline-Parallelisierung wiederum entstehen diese vor allem, wenn die Trainingsdatensätze in größere Pakete oder Batches geteilt werden. Effizienter ist es, die Daten in viele kleine Päckchen oder Mikro-Batches zu unterteilen.“ Der Verteilungsgrad von Modell-Layern und Datensätzen kann mit entsprechender Software an SNG-2 manuell gesteuert werden. Effizienter ist allerdings die Automatisierung dieser Aufgabe durch den Einsatz von Werkzeugen zur Hyperparameter-Optimierung. Auch das haben die beiden KI-Spezialisten untersucht.
Die praktischen Erfahrungen mit dem Training von Sprachmodellen auf SNG-2 dürften Forschende interessieren, die dafür bislang auf NVIDIA- oder AMD-Ressourcen setzen und Alternativen kennenlernen wollen. Ebenso spannend sind sie für Sprachwissenschaftlerinnen, die eigene Modelle entwickeln, sowie für Bioinformatiker, die Sprachmodelle mit Proteincodes oder -Sequenzen trainieren. Ob die Erkenntnisse generell auf das Training anderer KI-Modelle übertragbar sind, werden Rajgopal und seine Kolleginnen am LRZ in Zukunft ausprobieren und analysieren. „Wir planen außerdem“, fügt der Informatiker an, „bald ein Sprachmodell durchgängig zu trainieren und unsere Studie auf größere GPT-Modelle und weitere Verteilungsstrategien zu übertragen. Dabei werden wir außerdem den Energiebedarf und verschiedene Abläufe unter die Lupe nehmen.“ vs | LRZ
Beim Trainieren von Sprachmodellen waren im Einsatz
Alle Experimente wurden in der Standard-Softwareumgebung des LRZ sowie mit Software-Stacks ohne benutzerdefinierte Kernel oder Framework-Modifikationen durchgeführt.