Energy efficient exascale computing made in Europe

It should be as economical as possible and provide many new research methods: The European research projects DEEP SEA and REGALE are now delivering software stacks and tools for sustainable exascale supercomputing in Europe. Learn, what researchers can expect from the software packages.
The Data Centre Data Base (DCDB) is a monitoring tool that collects environmental, operational and performance data from sensors in data centres and their high-performance computers. Developed by the Leibniz Supercomputing Centre (LRZ), the open source program provides the data needed to operate various computer resources in a sustainably and economical, energy-efficient manner. In addition, the DCDB information shows where software or scientific applications can be adapted to the requirements of existing hardware in order to run more efficiently. "Energy consumption is becoming acritical issue for supercomputing and exascale systems," says Dr Josef Weidendorfer, head of the Future Computing research group at the LRZ. "While initial solutions are available on the hardware side with accelerators such as GPUs or FPGAs, the focus is now also shifting to operating systems, programming environments and applications."
Improving performance through monitoring
As demands for greater energy efficiency continue to grow, monitoring is becoming increasingly important in high-performance computing (HPC) and supercomputing centres. The need for monitoring and control is growing with the complexity of the resources installed there. In order to continue to deliver more performance and process growing volumes of data, supercomputers are now integrating Graphics Processing Units (GPU) in addition to Central Processing Units (CPU), which enable artificial intelligence (AI) methods and also accelerate computations. To reduce the carbon dioxide footprint from data centres, the power consumption of (super)computers must also be reduced. It is monitoring tools such as DCDB that provide the basis for measures. It is no coincidence that the tool has played a role in several European research projects, including DEEP SEA and its predecessors, as well as REGALE.
Launched in 2021, these two are now delivering practical results: DEEP-SEA eill provide an integrated open source software stack and the programming environments for a powerful exascale-class HPC in Europe, while REGALE is deliver the tools to make supercomputing more sustainable. In addition to the Ludwig-Maximilians-Universität and the Technical University of Munich, the computing centres of the Gauss Centre for Supercomputing (GCS) also collaborated on both projects.
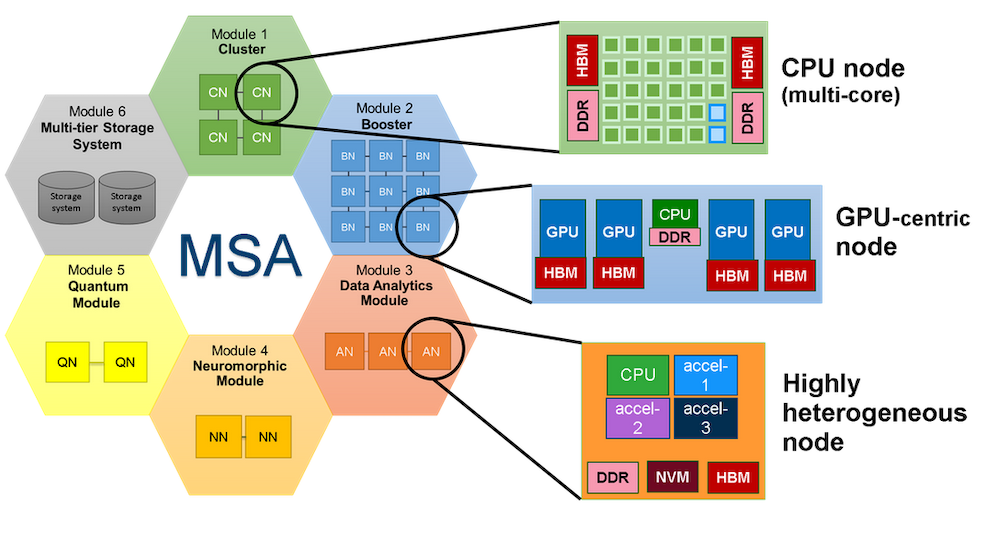
Software Architecture for a Modular System
"The DEEP projects have combined hardware and software technologies to design, operate and use heterogeneous HPC systems more efficiently," summarises project coordinator Hans-Christian Hoppe from the Jülich Supercomputing Centre (JSC). "The DEEP-SEA software stack integrates programming models, APIs, tools and software libraries. In particular, the abstraction of optimisation cycles, the support of hierarchical storage systems and the use of CI/CD techniques will bring direct benefits for HPC systems." Other projects add technologies and tools for organising flexible storage hierarchies and fast access to large amounts of data, as required by AI methods, as well as innovative networking and interconnection technologies for the computing systems.
The starting point for all developments in the DEEP projects is the Modular System Architecture (MSA), a concept for the first European exascale computer JUPITER, which is being built at Jülich and is scheduled to go into operation in 2024. However, integrated HPC systems such as LRZ's SuperMUC-NG Phase 2, which, unlike modular computers, combine different components and processor types in thousands of similarly structured computing nodes, can also use the tools and technologies developed. "The software developed in the DEEP projects is open source," explains Weidendorfer. "It is also published via the common HPC software package management Spack and EasyBuild, so it can be easily installed and used." The DEEP package provides computing centres and users with a wealth of useful tools for operating supercomputers and programming code and software. The portfolio ranges extends from the programming environment to monitoring and benchmarking tools. In addition to research institutions, companies that use HPC and operate corresponding systems wiil also be able to access DEEP technology. It is hoped that Europe's research and development activities will move closer together with comparable tools: "The aim was in fact also to improve collaboration by using a common software stack and to support the pooling of European HPC resources", says Hoppe. If there are familiar tools, databases and programming environments on the supercomputers, it is easier to access resources and exchange data.
AI supports HPC
The DCDB monitoring tool is also an important part of the REGALE tool chain. In this project, 16 research institutions and computing centres from across Europe have put together a toolbox of proven open source software that will support energy-efficient HPC. "Traditionally, the supercomputing way is to optimize software in order to take less time with energy savings coming automatically", says Dr Georgios Goumas, coordinator of REGALE and professor at the National Technical University of Athens (more in the interview below). "Modern computer systems are quite complex, they include several hardware components, each of which has a different power consumption profile and behavior. This is where REGALE comes into play, our tool chain supports energy-efficient operation and relieves users and administrators of tedious tasks." Managers of comoputibng centres, for example, can find instruments and tools to adapt clock frequencies to the workload of their systems or to constantly monitor its energy consumption. Users, on the other hand, can use REGALE tools to programme code to consume less power in certain phases and to create efficient, low-power workflows. "We see an increasing complexity and heterogeneity in system architectures. This makes energy efficiency and measures more difficult", Goumas says. "Interestingly, AI is a huge energy consumer of these large-scale facilities, but it can come also as a solution to the energy allocation problem. Further developments will address these points." (vs)
“The REGALE tool chain supports automatic and energy-efficient operation”
The crux of the matter with supercomputers is that they need too much energy to process research data. For science and data centres, this is not just a cost issue; researchers and computer specialists around the world are working to reduce pollutant emissions in high-performance computing (HPC). Now that accelerators such as graphics processing units (GPU) or field programmable gate arrays (FPGA) have significantly reduced the hunger for electricity on the hardware side, the focus is shifting to software programming: for the European REGALE research project, 16 universities, research institutions, data centres and companies have put together a software stack or tool chain from tried-and-tested tools that can now also reduce energy requirements during computing and programming. Among them are the Technical University of Munich (TUM) and the Leibniz Supercomputing Centre (LRZ). The tool chain is currently being used in five scientific pilot projects. The REGALE tools are being tested in day-to-day research to see how they can be used to control hardware components, in programming and in the development of software. Dr Georgios Goumas, Associate Professor at the National Technical University of Athens (NTUA) and coordinator of REGALE, and Dr Eishi Arima, computer scientist at the Technical University of Munich (TUM), will report on the aims and results of the REGALE project.
Has the European REGALE project achieved the goal of bringing more energy efficiency to supercomputing? Georgios Goumas: REGALE is indeed finishing this March its three-year endeavor during which we defined an open, modular and extensible architecture to support energy-efficient operation of supercomputing facilities. On top of that, we instantiated this architecture with alternative toolchains brought in the project by our partners and also implemented a framework to support modularity and interoperability for any tool by just adhering to an open API.
A package of open-source software was developed to control energy consumption - how did it come about? Goumas: In REGALE we followed two different paths: the first path proceeded to the implementation of what we call “integration scenarios” that glue together different tools which collaborate to support energy efficient operation at various levels of the architecture – compute node, multiple nodes, entire system. While this approach is effective for the specific tools embraced, it cannot be easily generalized to alternative tools. To address this challenge, we followed a second path, where we implement a core infrastructure that supports modularity and interoperability with a vision to support any tool with minimal modifications.
What complicates the control of power consumption in a High-Performance Computing System (HPC)? Goumas: Going back to the principles, energy is the product of work with time. The traditional “supercomputing” way is to optimize software in order to take less time with energy savings coming automatically. However, modern computing systems are quite complex, they include several hardware components, each one of them with different power consumption profiles and behavior. As we say, modern computing systems are not energy-proportional, their throughput, i.e. actual work done per second, is not necessarily directly related to the power they consume. The key concept that lies behind the more recent energy optimization approach is to make the components of the computing systems burn the energy required by the resource profile of the application under execution.
What can system administrators and users do to save energy during supercomputing and data analysis? Goumas: Users need to somehow understand the performance, scalability and energy behavior of their applications and adapt their requests accordingly. The tradeoffs between time to solution and energy are important to understand, and so is the energy footprint which, not surprisingly, may change during the year, even during the day and depends on various conditions like the weather, the power grid status, the availability of renewable energy and others. Administrators, on the other hand, apart from the above, have more control over their system and can for example take some crude decisions like powering on and off parts of their systems or throttle the power that they provide them with. I guess the above seems quite complex for users and administrators and maybe even largely ineffective. This is where REGALE comes into play to support automatic and effective energy-efficient operation, relieving the users and administrators from this cumbersome task. For example, the REGALE toolchain employing EAR and Examon can automatically detect phases of the application that are memory or communication heavy and allocate the distribution of power accordingly, in this case lower it, as compute power is not needed at its peak at these phases.
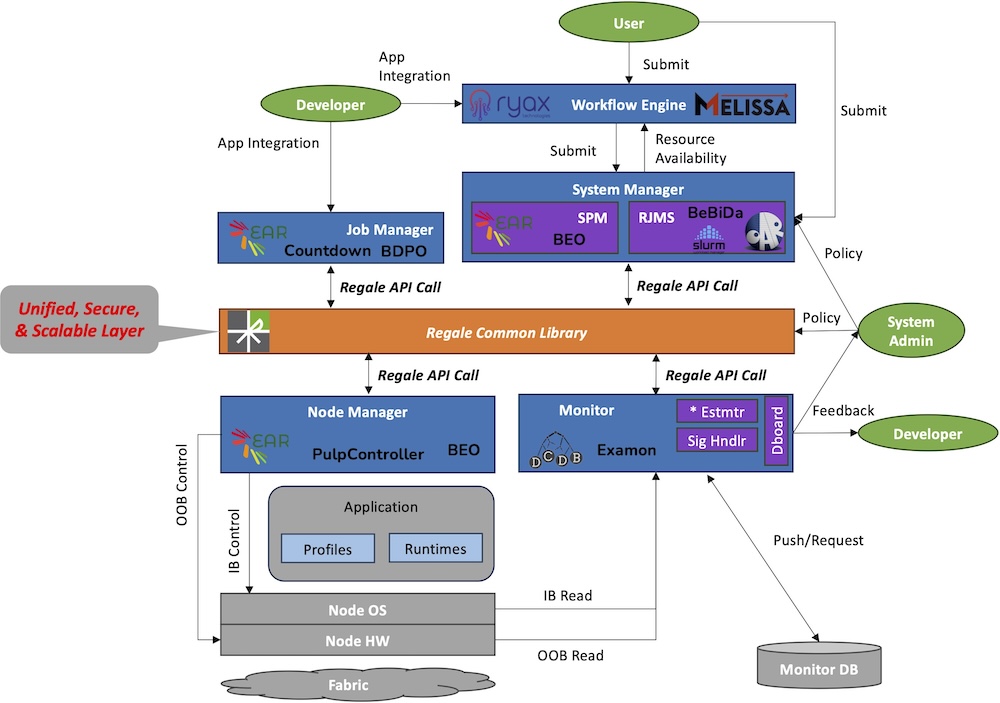
The scheme shows the areas, where the REGALE tools can work and support an energy efficient computing
The REGALE tools are primarily aimed at computing centres - who should definitely take a look at them and use them? Goumas: Our primary target users are the operators of supercomputing facilities. Dr. Eishi Arima. For instance, we have holistic system monitoring software, for example DCDB and Examon, as well as system-level power management tools, e.g. EAR and BEO, and they need to be installed and managed by the privileged site administrators. On the other hand, several tools are also relevant to application developers. As an instance, COUNTDOWN is a library that saves energy in MPI communication phases and needs to be linked to application codes. Another example is Melissa workflow engine that helps with realizing efficient ensemble runs often required in modern scientific applications.
Has the REGALE software package been fully or partially installed anywhere - and how has it worked? Goumas: Tools from the REGALE toolchain are already part of the software portfolio of some supercomputing centers. The integration process is ongoing and we are optimistic that we will deliver an effective and easy to use software stack. We need to do some more work in this direction, however.
How easy is it to integrate the tools into an existing architecture? (experiences) Goumas: Indeed, there are several challenges there, especially if you consider that supercomputers are huge machines, they serve hundreds, even thousands of users and are expected to be stable and functional. Any new toolchain, especially the ones that go at the heart of the machine operation to support efficient resource management, need to go through serious tests to ensure stability, security, effectiveness etc. This is by no means a straightforward process, but we are working on it.
16 partners, including computer centres, universities and software companies from all over Europe, were involved in REGALE - how did the collaboration go? Arima: In the early stage of the project, we focused on collecting use cases, clarifying architectural requirements, and defining the blueprint of integrations. As this was a high-level procedure to determine the general direction, all the partners were involved in. Once the integrations were determined, our collaborations became on a per-integration basis though we shared the progress across integrations in our regular meeting. Then, once each integration matured, several cross-integration collaborations also happened. As an example, the Melissa tool was first integrated with Pilot applications, which was later combined with a PowerStack integration to realize power-aware workflow management. We think this sort of hierarchical inter-/intra-task collaboration with having both top-down and bottom-up views is a key for this scale of project.
The REGALE team also shared ideas with the PowerStack community: What is it? Arima: The HPC PowerStack initiative was launched in 2018 in order to design a holistic and extensible power management framework, which we refer to as the PowerStack. In the community, we have held online/in-person meetings on an irregular basis to exchange ideas among experts from academia, research laboratories, and industry. The REGALE team inherited the baseline strawman architecture and its use cases from the community, revised/extended them to map the REGALE toolchain, and have integrated our software tools to realize the use cases. We are sharing our updates and lessons learnt from the entire procedures with them to drive the standardization effort led by the community.
What are the next steps? Energy efficiency is more of a journey than a challenge that can be set for a long time? Goumas: We have ahead of us an increasing scale of data centers making energy efficiency a top class priority. We also have an increasing complexity and heterogeneity of the system architecture. This makes measures more difficult. Interestingly, AI is not only a killer application, a huge energy consumer of these large-scale facilities, it can also come as a solution providing sophisticated solutions to the energy allocation problem. Further developments will address these points. (vs)


Prof. Gerorgios Goumas and Dr. Eishi Arima