
Die Rechner der VPP-Serie sind skalierbare, vektorparallele Rechner der Firma Fujitsu Ltd. Rechner dieses Typs werden seit der zweiten Hälfte 1996 an europäische Kunden ausgeliefert. VPP steht für "Vector Parallel Processor". Die VPP-Serie ist eine Weiterentwicklung der VP-, S- und VPP500-Serien und ist in den Modellreihen VX, VPP300, VPP700 und VPP5000 lieferbar. Die Modellreihen der VPP-Serie unterscheiden sich in der Maximalzahl der Prozessor-Elemente (VX: bis 4 PEs; VPP300: bis 16 PEs; VPP700: bis 256 PEs) und in der Gestalt des internen Netzwerks. Die lokalen Rechner der Typen VX und VPP300 an den bayerischen Universitäten sind mit dem Landeshochleistungsrechner vom Typ VPP700 am LRZ kompatibel.
Die VPP-Serie basiert auf CMOS-Technologie und ermöglicht damit niedrigen Stromverbrauch, geringe Wärmeabgabe und einen günstigen Preis. Die Rechner sind luftgekühlt. Ein CMOS-Chip der VPP-Systeme enthält etwa 8 Millionen Transistoren, und wird in einem 0,35 Mikrometer-Prozeß gefertigt. CPU, Speicher und - bei den VX- und VPP300-Modellen - das interne Netz sind auf einer Prozessorkarte der Größe 37 cm x 48 cm untergebracht. Die Hauptspeicher (MSUs) bestehen aus DRAM-Speicherchips, die eine Kapazität von je 16 MBit und eine Zugriffszeit von 60 ns haben.
Jedes Prozessor-Element (PE) der VPP-Serie verfügt über eine Vektoreinheit mit einer Spitzenleistung von 2,2 GFLOPS und einen lokalen Hauptspeicher mit wahlweise 2 GByte oder 0,5 GByte. Am LRZ wurde die 2 GByte Version gewählt. Eine voll ausgebaute Maschine der Baureihe VPP700 mit 256 Prozessoren hätte eine Spitzenleistung von 563 GFLOPS und insgesamt 512 GByte verteilten Hauptspeicher.
Die PEs kommunizieren über ein homogenes, konfliktfreies Kreuzschienen-Netz (crossbar network). In diesem internen Netz sind alle PEs gleichberechtigt; bei der Parallelisierung von Programmen muß die Netzwerktopologie nicht berücksichtigt werden.
Hinsichtlich Betrieb und Verwaltung der Maschine spielt das PE0 (primary PE, P-PE) eine ausgezeichnete Rolle; auf diesem PE läuft z.B. NQS, das System zur Auftragsbearbeitung. Das PE0 verwaltet auch - vor allem bei kleineren Anlagen - die angeschlossenen Platten.
Alle PEs arbeiten im Wesentlichen auf einer einheitlichen gemeinsamen Dateibasis.
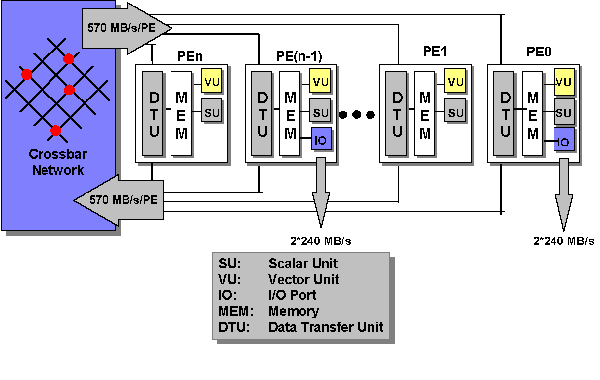
Abbildung: Systemarchitektur des VPP
Am LRZ steht ein Rechner des Typs VPP700/52, d.h. eine Maschine mit 52 Prozessor-Elementen mit je 2 GByte Hauptspeicher. Er ist mit einem Plattenspeicher von insgesamt 1214 GByte ausgestattet, wovon 1123 GByte auf RAID-Plattensystemen zur Verfügung stehen. Die RAID-Platten sind zu gleichen Teilen an insgesamt 5 PEs (sog. IMPEs, IPL Master PEs, die auch I/O abwickeln) angeschlossen; eine Ausnahme bildet das Gen5-XLE-Plattensystem, auf dem insbesondere das Dateisystem /ptmp_vfl_large für große Projekte liegt. Das primäre PE betreibt nur Systemplatten und Netzanschlüsse. Die 5 IMPEs sind ebenfalls mit Netzanschlüssen (FDDI) ausgerüstet.
| Zahl Prozessor-Elemente (PEs) | 52 |
| Hauptspeichergröße in GByte | 104 |
| Plattenkapazität in GByte | 1214 |
| Taktzeit in ns | 7 |
| Taktfrequenz in MHz | 143 |
| Zugriffszeit des Hauptspeichers in ns | 60 |
| Max. Vektorleistung pro PE in GFLOPS | 2,2 |
| Max. Skalarleistung pro PE in GFLOPS | 0,275 |
| Max. Vektorleistung der Maschine in GFLOPS | 114.4 |
Tabelle: VPP700 am LRZ
Der VPP700 am LRZ wird sowohl als Vektorrechner als auch als Parallelrechner betrieben. Das heißt, es gibt sowohl dedizierte PEs und zugehörige NQS-Jobklassen für sequentielle vektorisierte Programme als auch für parallele vektorisierte Programme. Parallele Programme, die nicht gleichzeitig vektorisierbar sind, sollten auf dem Linux-Cluster oder der IBM-SMP (Typ Regatta) gerechnet werden.
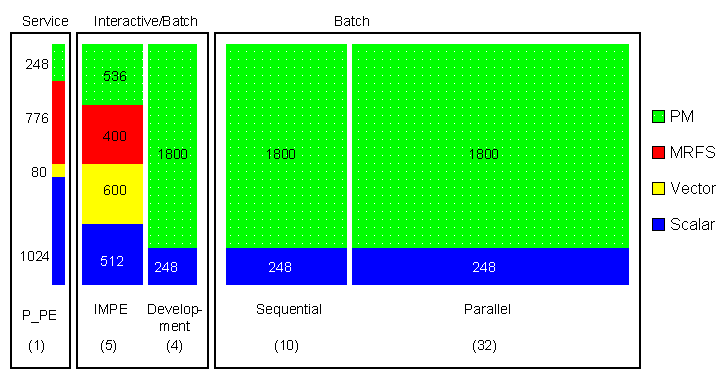
Abbildung: Memory-Konfiguration der VPP am LRZ, Angabe der Memorygröße jeweil in MByte.
Die VPP-Serie wird mit dem Betriebssystem UXP/V betrieben. Dies ist eine Variante von UNIX System V Release 4 und unterstützt die wesentlichen Elemente der Standards SVID Version 3, IEEE Posix 1003.1 und XPG3. Fujitsu hat einige Erweiterungen für den Betrieb in Rechenzentren vorgenommen. Auf jedem PE läuft eine Kopie dieses Betriebssystems, jedoch operieren alle Kopien auf einer einheitlichen Dateibasis. Benutzerprogramme können von allen PEs aus in gleicher Weise auf Dateien zugreifen.
Benutzer können sich mit SSH (Secure Shell) oder SCP (Secure Copy) mit jedem PE verbinden, das für interaktiven Zugang konfiguriert ist. Dies sind am LRZ die 5 IMPEs und das primäre PE. Stapelaufträge werden mit NQS verwaltet, welches auf dem primären PE läuft. Die Zuteilung von NQS-Jobs zu PEs erfolgt in Abhängigkeit von den angeforderten Betriebsmitteln durch das PMS (partition manager system). Benutzerjobs können ein PE exklusiv (simplex mode) oder zusammen mit anderen Jobs nutzen (shared mode). Die exklusive Nutzung von PEs ist am LRZ nur für Paralleljobs vorgesehen (paralleler Pool, s.u.)
Das Betriebssystem beherrscht virtuelle Speicherverwaltung (paging). Dies wird aber nur für skalare Programme, das sind im wesentlichen die Betriebssystemkommandos, genutzt. Benutzerprogramme sollen immer vektorisiert oder jedenfalls automatisch vektorisierbar sein (sonst ist der VPP der ungeeignete Rechner); Vektorprogramme sind jedoch auf den realen Hauptspeicher beschränkt und können allenfalls als ganzes auf Platte ausgelagert werden (swapping).
Das Betriebssystem UXP/V ist ein 32-Bit-System. Die Vektoreinheiten arbeiten jedoch mit Worten von 64 Bit. Dabei werden ganze Zahlen auf Gleitkomma-Zahlen abgebildet, wobei effektiv nur 32 Bit zur Verfügung stehen; dies bedeutet, daß ganze Zahlen nur dann vektoriell verarbeitet werden können, wenn sie als integer*4 definiert sind (integer*8 geht nur skalar). Die Skalareinheit kann sowohl 32-Bit- als auch 64-Bit-Worte verarbeiten.
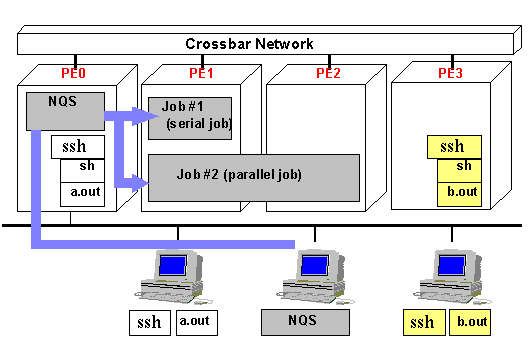
Abbildung: gleichzeitige Ausführung mehrerer Jobs auf dem VPP
Hauptbestandteile eines Prozessor-Elements sind die Skalareinheit (scalar unit, SU), die Vektoreinheit (vector unit, VU), der Hauptspeicher (main storage unit, MSU) und die Datentransfereinheit (data transfer unit, DTU). Beim primären PE und bei den IMPEs kommen noch Einrichtungen für Ein-/Ausgabe hinzu. Sowohl die Skalareinheit als auch die Vektoreinheit führen Gleitkomma-Arithmetik nach dem Standard IEEE-754 durch und sind damit mit den anderen Supercomputern des LRZ und mit Workstations kompatibel.

Abbildung 3: Blockdiagramm eines PEs (Anklicken für Details)
Die Skalareinheit arbeitet nach dem RISC-Prinzip mit langem Instruktionswort (LIW, 8 Byte), das die parallele Bearbeitung von bis zu 3 Operationen pro Maschinenzyklus ermöglicht. Gleitkomma-, Vektor, Speicher- und Kommunikationsoperationen können parallel gestartet werden und werden asynchron ausgeführt. Zwei der drei Operationen können Gleitkomma-Arithmetik durchführen. Damit kann in der Spitze eine Befehlsrate von über 400 MIPS und eine skalare Gleitkomma-Leistung von 275 MFLOPS erreicht werden.
Die wesentlich schnellere Verarbeitung von vektorisierbaren Operationen (bis 2,2 GFLOPS) gegenüber den skalaren Operationen (bis 275 MFLOPS) zeigt, daß dieser Rechner nur für vektorisierbare Programme eingesetzt werden soll. Für rein skalare Programme sind das Linux-Cluster oder die IBM-SMP am LRZ die besseren und vermutlich auch schnelleren Maschinen.
Üblicherweise nutzen parallele Programme diese Maschine als Distributed Memory Maschine, wobei auf jedem PE ein Prozess mit eigenem Adressraum abläuft. Die Prozesse eines parallelen Programmes tauschen dann Daten via Message Passing aus. Für spezielle (daten)parallele Fortran-Prozesse kann die Data Transfer Unit (s.u.) auch einen virtuell globalen Speicher, der sich über mehrere reale Hauptspeicher (MSUs) erstreckt, realisieren. Bei der Nutzung von derzeit maximal 16 PEs steht dann ein globaler Speicher von maximal etwa 28 GByte zur Verfügung.
Die Transferaufträge werden in einer Warteschlange gespeichert und nacheinander abgearbeitet. Ein einzelner Transfer kann bis zu 16 MByte übertragen. Außerdem verfügt die DTU über ein Register für die schnelle Barrier-Synchronisation.
Das interne Netz wächst linear mit der Zahl der PEs. Bei 52 PEs beträgt die gesamte Transferleistung in der Spitze 52 x 570 Mbyte/s.
Dateien werden - abgesehen von den Systemdateien - auf drei unterschiedlichen Arten von Platten-Systemen in RAID-Technologie gehalten: (1) fünf langsame Platten-Systeme des Typs F6401H von der Firma Hitachi mit einer Gesamtkapazität von 248 GByte und einer maximalen Übertragungsrate von 20 MByte/s pro System; (2) vier schnelle Platten-Systeme des Typs Gen5L von der Firma Maximum Strategy mit einer Gesamtkapazität von 510 GByte und einer Übertragungsrate von 70 MByte/s; (3) ein schnelles neues Platten-System des Typs Gen5-XLE von der Firma Maximum Strategy mit einer Gesamtkapazität von 364 GByte und einer Übertragungsrate von 62 MByte/s. Permanente Benutzerdateien liegen auf den langsameren Platten, temporäre Dateien auf den schnellen.
Die Platten werden zu gleichen Teilen an die 5 IMPEs angeschlossen; Ausnahme: Gen5-XLE-Plattensystem mit dem Dateisystem /ptmp_vfl_large für große Projekte. Damit zerfällt die Plattenbasis in zehn Teile, die den verschiedenen Benutzergruppen (TU München, LMU München , Erlangen etc.) zugewiesen werden.
Auf den Platten werden zwei Arten von Dateisystemen mit stark unterschiedlicher Charakteristik eingerichtet: Der Standardfall ist ufs (UNIX Filesystem). Daneben gibt es Filesysteme vom Typ vfl-fs (very fast and large file system), welche nur für wirklich große Dateien geeignet sind und unter Umgehung einer Systempufferung genutzt werden.
Für den Benutzer ergibt sich folgende Sicht auf die Filesysteme:
Home-Filesysteme
Diese enthalten die permanenten Benutzerdateien wie Programmquellen, kleinere
Eingabedatensätze, wichtige Ergebnisdaten etc. Diese Dateisysteme
werden vom LRZ in regelmäßigen Abständen gesichert. Der
Benutzer kann über die Environmentvariable $HOME auf seine Daten zugreifen.
Ein Kontingentierungssystem überwacht dynamisch den Umfang und die
Zahl der Dateien.
Temporäre Filesysteme
Ein direkter Zugriff auf das in der Unix-Welt übliche Filesystem
/tmp ist aus Gründen des reibungslosen Betriebs nicht
sinnvoll. Unberechtigt dort angelegte Files werden deshalb vom LRZ nach
relativ kurzer Zeit entfernt.
Statt dessen kann jeder Benutzer auf ein job-temporäres
Verzeichnis über die
Environmentvariable $TMPDIR zugreifen. Die dort abgelegten Daten und das
Verzeichnis $TMPDIR werden nach Jobende vom LRZ gelöscht.
Die Verzeichnisse $TMPDIR liegen im pseudotemporären Dateisystem (s.u.) vom
Typ UFS; sie unterliegen jedoch nicht der Gleitlöschung, damit die
Existenz dieser Dateien bis zum Ende des jeweiligen Jobs gesichert ist.
Bitte beachten Sie aber, daß die Dateien in $TMPDIR und in $PTMP_UFS
dem gleichen Plattenkontingent unterliegen.
Pseudotemporäre Filesysteme
Diese enthalten Datensätze von Benutzern (z.B. Ausgabedaten, Eingabedaten
für Folgeläufe), die mittelfristig aufgehoben werden sollen (ca.
2-4 Wochen).
Durch das LRZ erfolgt keine Sicherung dieser Daten
, da die zu erwartende
Datenmenge in kürzester Zeit ein Archivierungssystem sprengen würde.
Die pseudotemporären Filesysteme unterliegen einer
Gleitlöschung,
d.h. wenn der Füllungsgrad eines Filesystems eine bestimmte Marke
überschreitet, werden solange alte Dateien gelöscht, bis wieder
ein Füllungsgrad unter einer bestimmten Marke erreicht ist. Das Anstoßen
des Löschmechanismus ist, unabhängig von der Menge an Daten,
die ein spezieller Benutzer anlegt, sondern hängt davon ab, wie alle
Benutzer das Dateisystem gefüllt haben. Gleichwohl gibt es für
jeden Benutzer Grenzwerte, um das versehentliche Vollschreiben der
Filesysteme zu verhindern. Jeder Benutzer kann seine Daten in zwei pseudotemporären
Filesystemen ablegen:
Filesystem für große Projekte:
/ptmp_vfl_large
Das Dateisystem /ptmp_vfl_large dient der Bearbeitung einzelner
Projekte mit grossem Platzbedarf. Es steht allen Nutzern des VPP700 offen.
Die Berechtigung zur Nutzung wird jedoch nur auf Antrag und nur
für beschränkte Zeit gewährt. Antrag am besten per Email
an vpp-admin@lrz-muenchen.de.
Memory Resident Filesysteme
Programme, die mit hoher Frequenz kleine Dateien nutzen (z.B. Compiler),
können diese in den Hauptspeicher legen und damit eine erhebliche
Leistungssteigerung erreichen. Dazu werden vom Systemverwalter und/oder
Benutzer sog. mrfs (memory resident file system) eingerichtet.
Ein mrfs kann eine Transferrate von 600 MByte/s erreichen. Der Speicherplatz,
den das jobtemporäre mrfs verbraucht, wird dem Benutzerjob
angerechnet. Nach Beendigung des Jobs wird das jobtemporäre mrfs
gelöscht, so daß alle Dateien, die erhalten bleiben sollen,
auf ein plattenbasiertes Filesystem wie $HOME oder $PTMP kopiert werden
müssen. Insgesamt stellt die Verwendung von mrfs die schnellste
I/O-Art dar.
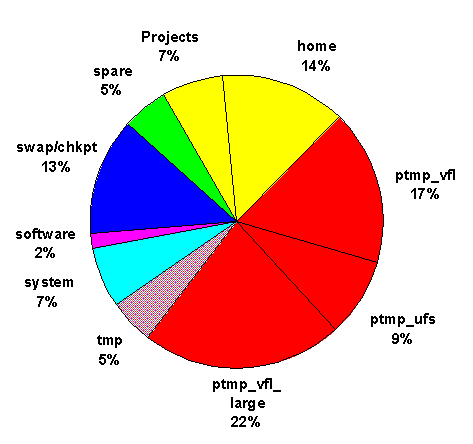
Abbildung: Relative Größe der Filesysteme an der VPP
Zur langfristigen Archivierung von Daten steht an der VPP700 ein ADSM-Client zur Verfügung, mit dem der Benutzer bequem Daten in das robotergestützte Archivierungssystem des LRZ übertragen kann.




