Batch & Interactive Jobs and Policies
An introduction to preparing and configuring a job for batch processing on the HLRB-II (sgi Altix 4700).
Table of contents
- Login to HLRB II
- PBS Batch Jobs and Interactive PBS Shells
- Interactive PBS Shells
- Batch Queuing Commands
- Batch Options
- Examples for queued Batch jobs
- Run time limits and default partitions for jobs
- Four step for configuring a PBS job
- Some specialities of and problems with the PBS configuration at LRZ
- Understanding the Details: Partitioning of HLRB II
- Documentation
Login to HLRB II
Please read the Introduction to HLRB for information about login and and interactive access before studying this document, which informs you how to use an interactive shell to test your parallel programs, or to submit a job for production runs.
We urgently ask you to not start any large and/or long-running programs, and not start parallel programs from your login shell. Please use an interactive PBS Shell as described below for this purpose; the login cpuset (30 cores only) is shared by all users on the machine, while much more cores can be provided in sum to interactive PBS jobs.
PBS Batch Jobs and Interactive PBS Shells
PBS Pro (the Portable Batch Queuing System) is used for the job management. There are two way running parallel jobs on the HLRB II
- Interactive PBS Jobs, typically for program development, testing, and debugging
- PBS Batch Jobs, typically for production load
Interactive PBS Shells
Interactive PBS Shells must be used to obtain exclusive use of CPUs for a limited amount of time.
- they provide you with an interactive environment into which you type your commands
- you must provide the resources you need on the qsub command line
- the -I switch must be provided to qsub
Examples:
|
qsub -I -l select=32 -l walltime=00:10:00 -v DISPLAY
will give you opportunity to run 32 MPI tasks any time within a 10 minute window from the start of the job. |
qsub -I -l select=8:ncpus=2 -l walltime=00:10:00-v DISPLAY
will give you opportunity to run 8 MPI tasks each having 2 threads any time within a 10 minute window from the start of the job. The environment variable OMP_NUM_THREADS is set to 2 |
Of course the intent is to start the job immediately, but that is only possible if sufficient resources are free on the machine. If not, you will need to wait anyway - but hopefully not very long due to the relatively short maximum run time for these jobs, so do not kill the waiting job!
Here some further hints and remarks on interactive PBS shells:
-
startup of the interactive PBS shell can take up to 10 minutes even if the resources are available.
-
if you need to run X11 applications from the PBS shell, please add the switch -v DISPLAY to the command line
-
immediately exit the interactive PBS after completing your test, typically by typing "exit". The blocked resources will be fully deducted from your CPU budget even if you do not run a program!
-
also keep in mind that other users might need the processors which you block
-
Please do not specify a command or shell script as an additional argument for qsub -I. You must start up any program which should run after the interactive shell returns with a prompt.
-
The cores will always be allocated in the density partition.
Limits for interactive PBS Jobs
- The default time limit for an interactive PBS job is 30 minutes.
- Maximum specifiable walltime is 4 hours (04:00:00)
- Maximum specifiable number of cores is 64
Batch Queuing Commands
Submission of Jobs
The qsub command can be used to submit a job into the queue. Usually it will be sufficient to perform:
qsub myscript
The command will return the job identifier. You can refer to this identifier in other PBS commands. Any parameters provided to qsub will overwrite the corresponding settings in the script. Changes to the PBS parameters can also be performed after job submission via the command
qalter <new_parameter_values> <job_id>
Querying the status of jobs
The qstat command can be used to query the status of jobs on the system. The recommended way to do this is to issue the command
qstat [-w] -a [-u <user_name>]
which will return a formatted text table of the following form:
Req'd Req'd Elap
Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time
--------------- -------- -------- ---------- ------ --- --- ------ ----- - -----
1001.pbs1 xxxyyy1 N128 job_1 -- 96 96 -- 24:00 H --
1002.pbs1 xxxyyy2 N256 job_2 5820 210 210 -- 24:00 R 08:30
1003.pbs1 xxxyyy1 N128 job_1 -- 96 96 -- 24:00 Q --
...
which lists jobs, their status (H - hold, R - running, Q - queued) and the requested vs. elapsed run times.
Note: jobs using 1000 or more CPUs need the -w (wider fields) option for output, otherwise last digits my be omitted.
Holding and releasing jobs
qhold <job_id>
will put a job into (user) hold. This means the script will not start execution until it is released again using the command
qrls <job_id>
Note that the PBS administrator may occasionally decide to put jobs into system hold; in this case the qrls performed by the user will not have any effect.
Removing jobs
qdel <job_id>
will remove a job from batch processing. This command also supports a forced job deletion via an additional -W force switch.
Signaling a job
qsig [ -s signal ] <job_id>
will send a signal to the job with the specified identifier. If no signal is provided, SIGTERM is delivered. For MPI jobs which want to use their own signal handler: Please be aware that with SGI MPT, only the signals SIGURG and SIGUSR1 can be used; all others are suppressed or will simply terminate the program.
Environment Settings
At execution time, a number of PBS-specific environment variables are available e.g., for controlling the execution flow of your script. The following table provides a description for some of these. Please consult the qsub man page for a complete list.
|
Name of Variable |
Meaning |
|---|---|
| PBS_ENVIRONMENT | Will have the value PBS_BATCH for a batch job and PBS_INTERACTIVE for an interactive (qsub -I) job. |
| PBS_NODEFILE | Points at the file containing the node configuration of the job. |
| PBS_JOBID | Provides the Job ID to the running script |
| PBS_O_PATH | Setting of PATH in the submission environment. |
| PBS_JOBNAME | Job name as specified e.g. with the -N parameter |
| PBS_O_WORKDIR | Working directory in the submission environment. Simply perform a cd $PBS_O_WORKDIR within your PBS script to return to the working directory from which the qsub command was issued. |
Batch Options
Batch job options and resources can be given as command line switches to qsub, or preferably, they are be embedded into a PBS job script as a comment line of the form. Options provided on the command line override values in the script.
#PBS option
for a PBS script. See the examples below for details.
General options |
||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
PBS option |
Functionality | Remarks | ||||||||||||
| (not directly available) | Start job in directory from which it was submitted. | not available as a parameter, but see above for a PBS environment variable you can use. By default, PBS starts the shell in your home directory. | ||||||||||||
| -M [mail_addr] | User's e-mail address. | obligatory so LRZ can contact you in case of problems. | ||||||||||||
| -m [a|b|e] | Batch system sends e-mail when [aborting|starting|ending] job. | recommended setting: -m abe. PBS accounting information is included in the mail which is sent with -m e |
||||||||||||
| -N [req_name] | Name of batch request. Default is name of the script. | 15 characters at most, must start with a letter. | ||||||||||||
| -o [filename] | write standard output to specified file. | LRZ recommends specifying the full path name. Default value is job_name.ojob_id, where job_name is the name of the job specified via the -N parameter, and job_id its identification number. If the path name only specifies a directory, a file with the name jobid.OU is generated within this directory. | ||||||||||||
| -e [filename] | write standard error to specified file. | LRZ recommends specifying the full path name. job_name.ejob_id is used as a default if no explicit name is specified. | ||||||||||||
| -j oe | write standard error to the same file as standard output | Any -e specification is ignored. | ||||||||||||
| -r n | Do not rerun job if system failure occurs | By default, job is rerun | ||||||||||||
| -v | Not available at HLRB | As LRZ uses a wrapper script for qsub, the functionality of setting environment varaibles in header part is not supported. Please set all environment variables in the body part of your job script | ||||||||||||
Job Control and Limits |
||||||||||||||
| -l walltime=hh:mm:ss | Specify wall time limit for job | hh hours mm minutes ss seconds. You should always provide this since the scheduler can improve your throughput using this information. If you need more than the standard run time limit you need to specially apply. |
||||||||||||
|
-l select=[N:]chunk[+[N:]chunk ...] |
Selection of configuration for parallel run and memory |
A select statement allows you to specify multiple chunks of (certain) resources. This is especially useful if you wish to run multi-partition jobs, or if each chunk requires slightly different resource settings (e.g., for MPMD parallel jobs).
Syntax: -select=N:ncpus=xx:mpiprocs=xx:ompthreads=xx:mem=xx
Examples: Standard single-partition job: #PBS -l select=4:ncpus=2 High memory job: #PBS -l select=8:mem=7gb Varying resources: #PBS -l select=400:ncpus=1+200:ncpus=2 Please contact LRZ HPC support if you have problems with the setup of these jobs. |
||||||||||||
|
-l bandwidth= [true|false] -l density= |
Specify whether to run job on high-bandwidth blades (true) or whether not to care (false).
Specify whether to run job on high-density blades (true) or whether not to care (false). |
These settings should only be used if the scheduling defaults are not suitable for some reason. The following restrictions apply:
|
||||||||||||
| -l nightrun=true | Specify whether to run a night time job | For short-running jobs (up to 8 hours) with at most 64 CPUs this resource can be specified. | ||||||||||||
| -l place=pack | Place all chunks on one partition. | We recommend against using this in favour of a suitable select clause. A job requesting more cores in packed mode than available in a partition will not be started. | ||||||||||||
Examples for queued Batch jobs
MPI jobs
MPI jobs can be of the following kinds:
- SPMD (single program multiple data): Only one executable
- MPMD (multiple programs multiple data): More than one executable with consistent communication structure in a single MPI_COMM_WORLD. As a special case of this, the executable may also be the same on all nodes. For example, a particular placement of tasks within the system can be enforced (see partition separation below) by using this method
Normal MPI jobs run with as many tasks as CPUs are provided. Note that OMP_NUM_THREADS is automatically set to 1. Explicit placement should normally not be needed since the MPI_DSM_DISTRIBUTE variable is automatically set. High Memory requirements may change this.
| SPMD Job | MPMD Job |
|---|---|
#!/bin/bash #PBS -o /home/hlrb2/group/user/mydir/myjob.out #PBS -j oe #PBS -S /bin/bash #PBS -l select=280:ncpus=1 #PBS -l walltime=12:00:00 #PBS -N myjob #PBS -M Mail_Address #PBS -m abe . /etc/profile.d/modules.sh cd mydir mpiexec ./myprog |
#!/bin/bash #PBS -o /home/hlrb2/group/user/mydir/myjob.out #PBS -j oe #PBS -S /bin/bash #PBS -l select=280:ncpus=1 #PBS -l walltime=12:00:00 #PBS -N myjob #PBS -M Mail_Address #PBS -m abe . /etc/profile.d/modules.sh cd mydir mpiexec -n 30 ./myprog1 : -n 250 ./myprog2 # Please explicitly specify the CPU numbers in the # mpiexec command. By default, the full number of # assigned CPUs is given to each binary, which is # probably not what you want. |
PBS assigns 280 CPUs for the job, which are then used by the MPI program, which is started up using mpiexec. For the MPMD Job, 30 of the 280 cores are used for myprog1, the other 250 for myprog2.
OpenMP Shared memory jobs
This job type refers to programs using POSIX threads, OpenMP or some other variant of shared memory parallelism. The second script also contains a placement (via the dplace command), which may be a good idea to use to keep the additional memory sockets requested near to the active core making use of it.
| Standard Job | High memory requirement Beware unused CPUs! |
|---|---|
#!/bin/bash #PBS -o /home/hlrb2/group/user/mydir/myjob.out #PBS -j oe #PBS -S /bin/bash #PBS -l select=1:ncpus=8 #PBS -l walltime=12:00:00 #PBS -N myjob #PBS -M Mail_Address #PBS -m abe # OMP_NUM_THREADS is set by PBS . /etc/profile.d/modules.sh cd mydir ./myprog |
#!/bin/bash
#PBS -o /home/hlrb2/group/user/mydir/myjob.out
#PBS -j oe
#PBS -S /bin/bash
#PBS -l select=1:ncpus=8:mem=56gb
#PBS -l walltime=12:00:00
#PBS -N myjob
#PBS -M Mail_Address
#PBS -m abe
# OMP_NUM_THREADS is set by PBS
. /etc/profile.d/modules.sh
cd mydir
NSOCK=$(($OMP_NUM_THREADS * 2 - 1))
dplace -x2 -c0-${NSOCK}:2 ./myprog
# Note that the above relies on PBS assigning
# twice the number of sockets than threads. We
# space out the threads to keep the extra memory
# per thread near to the core using it.
# Preferably use the script below
|
| Alternative high memory script | |
#!/bin/bash
#PBS -o /home/hlrb2/group/user/mydir/myjob.out
#PBS -j oe
#PBS -S /bin/bash
#PBS -l select=1:ncpus=16
#PBS -l walltime=12:00:00
#PBS -N myjob
#PBS -M Mail_Address
#PBS -m abe
# OMP_NUM_THREADS is set by PBS
. /etc/profile.d/modules.sh
cd mydir
export OMP_NUM_THREADS=8
export NSOCK=15
dplace -x2 -c0-${NSOCK}:2 ./myprog
# We space out the threads to keep
# the extra memory per thread near to the core
# using it.
|
Hybrid MPI+OpenMP jobs
The model provided here is a uniform one: Each MPI Task uses the same number of threads. The omplace command must be used to assure the threads are not concentrated on a single core
| SPMD Job | MPMD Job |
|---|---|
#!/bin/bash #PBS -o /home/hlrb2/group/user/mydir/myjob.out #PBS -j oe #PBS -S /bin/bash #PBS -l select=32:ncpus=4 #PBS -l walltime=12:00:00 #PBS -N myjob #PBS -M Mail_Address #PBS -m abe . /etc/profile.d/modules.sh cd mydir export MPI_OPENMP_INTEROP=yes mpiexec omplace ./myprog |
#!/bin/bash #PBS -o /home/hlrb2/group/user/mydir/myjob.out #PBS -j oe #PBS -S /bin/bash #PBS -l select=64:ncpus=4+128:ncpus=2 #PBS -l walltime=12:00:00 #PBS -N myjob #PBS -M Mail_Address #PBS -m abe . /etc/profile.d/modules.sh cd mydir # Variable MUST be set for hybrid codes export MPI_OPENMP_INTEROP=yes export MPI_OMP_NUM_THREADS=4:2 mpiexec -n 64 omplace ./myprog1 : -n 128 \
omplace ./myprog2
|
In the SPMD case, PBS assigns 128 CPUs for the job, which allows for 32 MPI Tasks with 4 threads per task. In the MPMD case, PBS assigns 512 CPUs for the job, 64 tasks with 4 threads each are run with myprog1, 128 tasks with 2 threads each are run with myprog2. One partition will not be sufficient to run this job, but there is no guarantee that all myprog1 tasks will be run on one partition, and all myprog2 tasks on another partition. In order to enforce the use of exactly one partition for each executable, please use the setup described in the next subsection
Jobs with predefined chunk size
| SPMD Job with partition separation |
|---|
#!/bin/bash #PBS -o /home/hlrb2/group/user/mydir/myjob.out #PBS -j oe #PBS -S /bin/bash #PBS -l select=2:ncpus=500:mpiprocs=250:ompthreads=2 #PBS -l walltime=12:00:00 #PBS -N myjob #PBS -M Mail_Address #PBS -m abe . /etc/profile.d/modules.sh cd mydir mpiexec omplace ./myprog1 |
Note: In this example, 2 chunks with 500 cores are used. In case of high bandwidth communication requirements, this method can be used to prevent distribution of a job's resources to many partitions in small portions or in portions which are not adequate for the algorithm., possibly at the cost of a longer waiting period in the wait queue.
Partition separated setups
| MPMD Job with partition separation |
|---|
#!/bin/bash #PBS -o /home/hlrb2/group/user/mydir/myjob.out #PBS -j oe #PBS -S /bin/bash #PBS -l select=1:ncpus=128:mpiprocs=32:ompthreads=4+1:ncpus=128:mpiprocs=64:ompthreads=2 #PBS -l walltime=12:00:00 #PBS -N myjob #PBS -M Mail_Address #PBS -m abe . /etc/profile.d/modules.sh cd mydir export MPI_OPENMP_INTEROP=yes export MPI_OMP_NUM_THREADS=4:2 mpiexec -n 32 omplace ./myprog1 : -n 64 omplace ./myprog2 |
Note: In this example, small numbers of chunks of large sizes are used. The separation is a consequence of the fact that each chunk must be run on one partition; the chunk sizes are properly fixed by specifying the mpiprocs and ompthreads parameters. Do not forget to specify the ncpus value since this will determine the number of cores actually assigned to each of the two chunks. This method can also be used for SPMD execution, for example to prevent distribution of a job's resources to many partitions in small portions, possibly at the cost of a longer waiting period. Here an example select clause for the SPMD case:
#PBS -l select=4:ncpus=510:mpiprocs=510:ompthreads=1
will use 4 chunks of 510 cores each, and enable you to start 2040 single-threaded MPI processes on (exactly) four partitions.
Sequential jobs
This type of job should only be needed in special circumstances, normally you should be running parallel jobs. Before deciding on submitting a serial job, please try to bundle multiple equi-balanced tasks into a parallel job!
#!/bin/bash #PBS -o /home/hlrb2/group/user/mydir/myjob.out #PBS -j oe #PBS -S /bin/bash #PBS -l walltime=0:30:00 #PBS -N myjob #PBS -M Mail_Address #PBS -m abe . /etc/profile.d/modules.sh cd mydir ./myprog |
Run time limits and default partitions for jobs
For all jobs (batch and interactive) the run time limits specified in the following table apply:
Batch run time limits |
||||
|---|---|---|---|---|
| Job Class: | job size (cores) |
run time limit (hours) |
Default |
run time limit (hours) |
| N64 | 1-64 | 48 | Density or Bandwidth |
Serial or small-scale parallel runs. May also be scheduled to fill small holes in partitions. Use multiples of 2 (even for serial runs!), and if you specify -l density=true, use multiples of 4. |
| N128 | 65-128 | 48 | Density or Bandwidth |
Small-scale parallel runs. Will be run on a single partition. |
| N256 | 129-256 | 48 | Density or Bandwidth |
Medium-scale parallel runs. Will be run on a single partition. |
| N510 | 257-510 (257-508) |
48 | Bandwidth | Medium-scale parallel runs; can be run on a single partition if properly configured (ncpus=...) . If you specify -l density=true, only up to 508 cores can be requested. |
| N1020 | 511-1020 | 32 | Bandwidth | Large-scale parallel multi-partition runs. (-l density=true is possible, but not recommended) |
| N2040 | 1021-2040 | 12 | Bandwidth | Large-scale parallel multi-partition runs (-l density=true is possible, but not recommended). |
| N4080 | 2041-4080 | 12 | Bandwidth | Very large-scale parallel multi-partition runs. (-l density=true is possible, but not recommended). |
| special | >4080 | no explicit limit | Bandwidth | This job class is for jobs which need more than 4080 CPUs or more wall time than the job classes specified above. You need to apply for access for this queue. This type of job may be scheduled to a mixture of high-density and high-bandwidth blades, hence special care is required in setting this kind of job up properly. |
| np_S64 | 1-64 | 8 | Density | Small-scale runs on the node which is used for interactive jobs at day. These jobs will only run at night (8 pm - 8 am). It is necessary to specify the nightrun property to differentiate the job from a standard small-scale parallel job. |
| N64L | 1 - 64 | 96 | Density | serial or small-scale parallel runs with wall clock requirements of more than 48 hours. Use multiples of 4 (even for serial runs!). |
LRZ will favor large parallel jobs with respect to scheduling.
If jobs with special requirements with respect to run time and/or CPU count need to be run, your user account can be validated for access to the special queue upon request. Please contact LRZ HPC support for access to this job class, providing a compelling technical reason for your request. Note that very large and thus expensive jobs may need direct supervision by LRZ personnel as well as the submitting user.
Four step for configuring a PBS job
The new system is in some respects more complex to use than previous ones; this is partly due to its size, and partly due to the higher flexibility offered by the large shared memory partitions. There are simply more possibilities. Hence, we've drawn up a 4 step recipe for the construction of PBS job scripts from your resource requirements which we hope covers most application scenarios which will run on the system. If you have special requirements please contact LRZ HPC support.
Step 1: Determine what kind of programs shall run
Rationale: Various configurations of (parallel) processing are possible, depending on the programming model used by your application.
Answer:
- MPP style processing: This is the run-of-the-mill MPI program, where each MPI task uses exactly one processing core; the quantity MPI_Tasks will be used in the following to denote the number of MPI processes used. Multi-partition jobs are generally allowed for this case, up to the limit defined by PBS job policies.
- Shared memory processing: If your program uses pthreads, OpenMP or shared memory segments, the number Threads_per_Task will denote the number of processing cores assigned to the single task. Jobs of this kind must be configured to run on a single partition.
- Hybrid parallel processing: This covers e.g., using MPI and OpenMP simultaneously. The two numbers MPI_Tasks and Threads_per_Task are needed to characterize this kind of program run. Threads_per_Task may not exceed the partition size. Multi-partition jobs are possible, but must be configured such that each MPI task has sufficient resources to start all its threads on the same partition it runs on.
- Serial processing: For some purposes, for example pre- and postprocessing or archiving of data, also serial jobs using only a single CPU may be needed. Here special care might need to be taken of memory requirements, as described in Step 3 below. This kind of job should not be run on a large scale; the expensive resource Altix 4700 is meant to be used for large-scale parallel processing.
For PBS jobs the mpiexec command should normally be used to start up MPI programs (MPP or hybrid). For details on the mechanism used as well as alternatives please consult the Altix-specific MPI document. Please be aware that mpirun does not work for multi-partition jobs, at least not out of the box without non-trivial parameter settings.
Step 2: Decide on single-partition versus multi-partition job
Rationale: The Altix 4700 has non-uniform memory access which becomes more pronounced when going beyond a partition. This means that parallel programs may not scale as well for large CPU numbers; see the description of system partitioning above for the bandwidth decrease. On the other hand, users may need very many processors and/or very much memory, in which case multi-partition processing will be needed. Conversely, jobs should not be distributed among more partitions than necessary in order to avoid them scaling badly due to bandwidth constraints.
Procedure: There are two criteria you need to make your decision:
-
Calculate the number
Cores_Active := MPI_Tasks * Threads_per_Task
This will give you the number of active cores needed to fulfill your compute requirements. Note that for MPP processing, you must set Threads_per_Task to 1, and for pure shared memory processing, you must set MPI_Tasks to 1.
- Estimate the amount of memory Mem_Total required for your complete program. An upper bound is needed here.
Answer: If Cores_Active > 510 (508) OR Mem_Total > 1800 GByte (200 GByte per partition have been set aside for system or MPT xpmem purposes to be on the safe side) you need a multi-partition job, otherwise a single-partition job can be constructed. However this is not guaranteed by LRZ, since to achieve improved throughput jobs with less than 510 (508) cores may also (at least occasionally) be run across multiple partitions. Please see the section on partition separated jobs or the pack statement for details on how to enforce running large resource chunks on single partitions.
Step 3: Check whether explicit memory requirements are needed
Rationale: In order to do efficient processing, care must be taken to keep the used memory local to the processors accessing them. Otherwise, performance for your program will go down due to congestion of the NUMAlink network. Furthermore, more memory may be effectively required by your application than directly requested via allocate or malloc. One of the following situations can occur:
- Once an active socket runs out of local memory, further allocation requests go to memory physically located on other sockets. In user space and under PBS control, this can only happen within the CPU set assigned for your use. If you need that much memory, this situation cannot be avoided and will be handled by PBS by assigning additional inactive cores to your job.
- If, for example, the user space FFIO layer is used, you need to take this into account when calculating your per-task memory requirements. Otherwise your job will be forcibly removed from the system. Similarly, large automatic arrays may request additional memory in an unobvious way.
The above situations should be avoided by suitable scaling of the per-core or per-socket memory requirement of the application. On all partitions, up to approximately 3.5 GByte memory will be available per core in user space.
Procedure: Calculate the amount of memory used by each task
Mem_Task := Mem_Total / MPI_Tasks
Answer: If Mem_Task > 3.5 GByte * Threads_per_Task it is necessary to add a memory requirement containing the Mem_Task value to your job script; PBS will assign more than Cores_Active processors to your job.
At this point, please reconsider:
- If you believe the additional processors must remain unused and only their memory is needed, then contact LRZ HPC support. In this case the effective per-core job performance will be typically bad due to the inactive cores and the CPU time for unused cores will still be deducted from your budget! Furthermore there will be an additional performance impact due to access of memory via the NUMAlink network as described in the rationale above.
- If you believe that the additional processors might be used at least to some extent e.g., via library multithreading, then please go back to step 2 and reassess the Threads_per_Task and/or MPI_Tasks settings.
Step 4: Construction of a PBS job script
Rationale: We need to translate the resource requirements obtained above into something PBS understands. For this purpose, the PBS select directive should be used. Furthermore, a number of PBS control statements are obligatory or at least recommended to make your job run properly.
Answer: Here is a template suggestion for the control section of your PBS script. Please note that entries in blue need to be replaced with the appropriate numbers calculated in steps 1-3, while entries in green need to be replaced by information specific to your user account. Entries in orange can be replaced by a setting of your choice (but possibly in prescribed format).
| PBS script line | Description |
|---|---|
| #!/bin/bash | Only needed if script section also shall be executed as normal shell script |
| #PBS -o /home/hlrb2/group/user/job_xxx.out | Output path specification. Can use any existing shared directory path. |
| #PBS -j oe | Write standard error to output file |
| #PBS -S /bin/bash | Shell used by PBS. Must be consistent with line 1 (if present). |
| #PBS -l select=MPI_Tasks:ncpus=Threads_per_Task:mem=Mem_Task |
Select parallel configuration. This will automatically provide environment settings for parallel execution with mpiexec. The mem clause can be omitted if the memory requirements do not exceed what is available on the requested CPUs.
The ncpus part must always be specified, while the mem clause can be omitted if no excessive memory resources are needed. Typically ncpus equals the number of OpenMP Threads. ncpus must be less or equal 510 (508 on high-density partitions)! You can also use ncpus to specify bigger contiguous parts of the system which might improve the communication behaviour (here you need to specify mpiprocs and ompthreads, too). Otherwise if you specify bigger chunks, you have to wait longer to get these chunks allocated by the scheduler, because it is harder to find free contiguous processors in the system than to place the jobs arbitrarily. Please see the description below for further details, as well as an example for the possibility of a more refined usage of select. |
| #PBS -l walltime=hh:mm:ss | Run time of job. Must be within LRZ imposed limits for job to start. |
| #PBS -N myjob | Name of job. |
| #PBS -M Mail_Address | Valid mail contact. Used for notification by PBS as well as by LRZ if trouble arises. |
| #PBS -m abe | Notify at abort, begin and end of job. |
| . /etc/profile.d/modules.sh | First line of script executed at run time. Necessary to provide correct environment. |
Further command lines can be appended to this job script, using the specified shell language. Once complete, simply submit your script to PBS by providing its name as an argument to the qsub command.
A number of example job scripts for various situations are provided in a separate section. These sometimes deviate from the pattern provided above to give you an impression of the flexibility available on the system.
Some specialities of and problems with the PBS configuration at LRZ
Module environment not available
Due to a PBS bug in the setup of the environment the module environment is not initialized. For this reason, do not forget to add the line
. /etc/profile.d/modules.sh
for bash/sh/ksh or
source /etc/profile.d/modules.csh
for csh/tcsh to your script before using the module command. The example scripts given above also contain this line.
Array jobs not supported
Due to problems with performing proper scheduling and accounting, array jobs will not be processed. Please submit appropriately configured standard batch jobs.
Policies on Jobs in Hold
- for the duration of the hold jobs do not acquire processing priority
- after 8 weeks of hold, jobs are removed at the system administrators' discretion.
Error message "Please contact Administrator"
There presently still are bugs in PBS which result in CPU sets not being properly removed. While there is a partial workaround for this in the LRZ configuration, occasionally jobs will still fail at startup. In this case, there is unfortunately no alternative but to resubmit the job.
If the error persists, please contact LRZ HPC support, providing the job IDs which failed.
PBS output file not found
You have specified an output path for your PBS standard and error output, but cannot find it in the designated place. This may happen due to a system error, but more likely due to a missing e-mail address entry. In this case, output is written to your HOME directory, and the Job ID is appended to the output file name. In essence the -k oe option is set by LRZ in this case.
Job placed in hold after repeated startup attempts
This also may happen as a symptom of still existing PBS bugs; again the only way to cope is to remove the job with qdel and resubmit it; LRZ staff will make attempts to remove the system hold from jobs which run into this kind of trouble.
Troubleshooting PBS
Further possible problems you may have with job scripts and submission are treated in the batch section of the Troubleshooting document on the LRZ web server.
Explicit placement for multi-partition jobs
We've told you to use mpiexec for multi-partition jobs because mpirun won't do. Unfortunately, it is not possible to use dplace then. Hence, if the automatic placement performed by mpiexec does not work properly for you (performance problems), please contact LRZ HPC support.
Understanding the Details: Partitioning of HLRB II
The following sections will give hints on configuring your jobs. It it essentail to understand the partitioning of the HLRB II.
The 9728 cores (or 4864 sockets) of the phase 2 installation are organized in nineteen 512 core partitions, each of which runs a separate instance of the SLES 10 operating environment. One blade on each partition is dedicated to system services.
Most of the system is only accessible by batch processing, which is performed by the PBS Pro queuing system from Altair. Note that in phase 2, 1 socket = 2 processor cores. From here onward, a unit of 1 core is used to describe computational resources
A description of the structure of the HLRB-II compute units
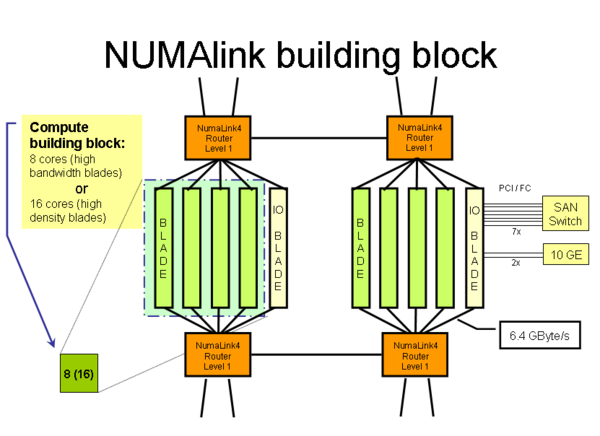
- Parallel NUMAlink building block: The smallest NUMAlink connected unit of the machine consists of 4 blades with 8 cores (high-bandwidth blades) or 16 cores (high-density blades) connected by two level 1 NL routers. Communication within this building block has the best possible bandwidth and latency characteristics.
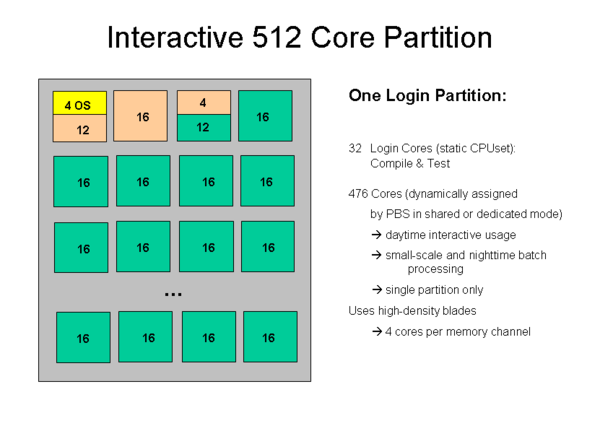
- Login and interactive partition: One 512 core partition will be configured with a 32 core cpuset within which login shells are placed for interactive and development work. The remaining 476 cores will be available for interactive usage under PBS control , night-time batch runs and small-scale parallel processing with long run times.
Due to the small number of cores of the login CPUset available for all users in shared mode, the login cores are not intended to be used for running large jobs or large MPI programs. Please use an interactive PBS shell to do large-scale testing and measurements. Large programs running on the login CPU set will be removed by LRZ personnel without advance warning.
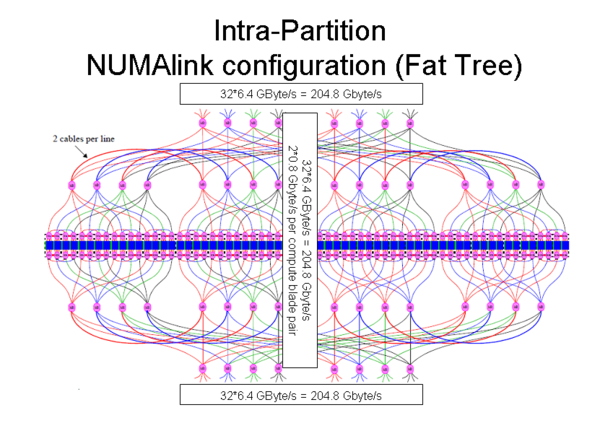
- 18 batch partitions: Up to 510 cores per partition (508 for high-density partitions) will be dynamically assigned for large-scale parallel batch processing. This number may still go down if the assignment of one blade for OS activity turns out to be insufficient.

-
Intra-partition processing: Batch jobs requiring up to 510 (508) cores can run on a single partition if appropriate PBS resource settings are specified. Within a partition, both distributed and shared memory processing (e.g., via OpenMP) are fully supported.
-
Multi-partition processing: Batch jobs requiring more than 510 (508) cores will need to use more than one partition; PBS may also distribute jobs with smaller core count across partitions to achieve improved filling of the machine. For the most part, only distributed memory processing is possible between processes/threads on different partitions.
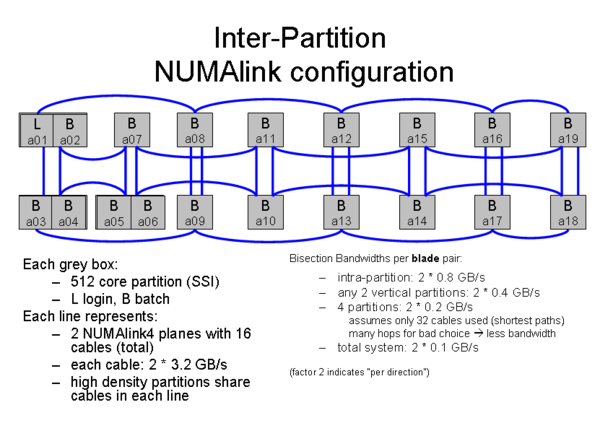
The drawing makes clear the NUMA characteristics with respect to bandwidth: Going from a single partition to a 4-partition configuration and then to the full machine decreases the bisection bandwidth available to a compute blade (i.e., 2 or 4 cores) each time. This may make it difficult to scale a parallel program to very high CPU numbers if lots of expensive communication calls (e.g., collective MPI calls) are used.
Documentation
The User's Guide (3.1 MB PDF, password protected). Please also consult the pbs man page, which provides information as well as references to further man pages.